AI CloudOS | AI 研发新范式
2022-06-22
4201
作者:行云创新 张磊
何为并发控制
这篇文章我们总结一下进程内的并发控制问题,主要是在高并发下的进程内部并发控制。
那么,什么是并发控制呢?
并发控制这个问题,从概念上讲,不难理解,个人觉得并发控制就是在多线程的环境下,控制请求或者任务的执行顺序,避免产生因为资源竞争导致的数据处理问题。
为什么要做多线程的并发控制?
这一切得从JVM底层的内存模型JMM(Java Memory Model)说起,设计Java的内存模型的主要目标是定义进程内各个变量的访问规则,也就是说在JVM内部,变量值的读取与存储的底层细节。JMM主要分为主内存和工作内存两个部分,根据周志明写的《深入理解Java虚拟机》一书中的描述,线程、工作内存和主内存之间的关系如下图所示:
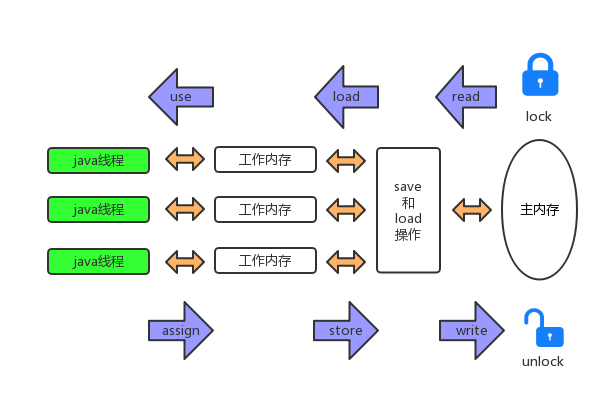
可以看到,图中一共有三个区域,线程执行区、工作内存、主内存,其中线程执行区和工作内存是线程独享的,也就是线程隔离的,而主内存也就是我们常说的堆里面存储对象实例数据所占用的内存,是线程共享的。JVM定义了8种内存间的交互操作,分别如下:
根据上面java内存模型定义中可以看到,java对象的数据都是在主内存中,每个线程要去使用的时候,首先要通过read-load操作,将主内存的数据加载到工作内存中,成为一个数据副本,后面线程执行引擎使用的时候,通过use-assign操作从工作内存中将变量副本加载出来用于栈上计算,用完后通过store-write操作将工作内存中的数据回写到主内存中。整个过程如果不做并发控制,用最基本的两个线程对同一个主内存数据操作来举例说明:

上图是最基本的多线程并发修改的示例图,两个线程同时对一个变量值a进行赋值操作,根据Java内存模型中定义的那几步操作来看,如果说不加锁控制的情况下,会发生如图中所示的场景,整形变量a初始值等于1,线程A对变量a进行加1操作,线程B对变量a进行加2操作,按理a最终应该为4,但是由于发生了并发修改,导致a最终为3,原因很简单,线程A在工作内存中修改了变量a的值,但是还没有往主内存中写的时候,线程B已经从主内存中读取变量a的值进行操作了,由于工作内存是线程隔离的,因此线程B并不知道线程A修改了变量a的值,导致线程B读取变量a的值是线程A修改之前的值,这个时候就发生了多线程的并发修改问题。因此,为了避免这种情况发生,我们应该对多线程的并发修改做控制,也就是今天的主题,进程内的多线并发控制。
如何做并发控制
之前的文章里面也聊到过并发控制,但是讲得比较浅,想在这里多聊一下并发控制相关的处理。一说到并发控制,可能很多人第一时间会想到锁,其实锁这个东西,不是个好东西,不得已的情况下,并不推荐用锁来实现并发控制。CPU是一个很昂贵的系统资源,现在一个CPU也就几十个核,CPU的计算资源很宝贵,线程执行的时候,是通过CPU的时间片轮转方式执行,如果进行线程上下文切换,那么会浪费CPU的时钟,因此一个核也就适合1-2个线程占用执行,如果通过锁的方式来控制并发,那么可能会产生大量的block,导致上下文切换,非常浪费CPU的时钟,所以锁是最后考虑的用作同步的方式。
进程内的队列使用
如果多线程内并发处理的地方比较多,那么看看能否从设计的角度来规避这个问题,例如事件驱动模型中,将多个线程中的请求,通过Disruptor的方式,聚合到一个线程中去处理,这个比较适合SEDA这种线程并发结构,如下图所示:

这样可以规避多线程的并发处理问题,当然并不是说所有多线程并发控制都适合这么做,这是一种规避并发控制的思路,可以参考。
集合的合理使用
高并发下的集合使用,可能会想到ArrayList、HashMap这类没有做并发控制的集合,在高并发下,要使用Collections的synchronized方法,转换成装饰过的类来进行并发控制,如果是HashMap的话,采用ConcurrentHashMap来进行并发控制,ConcurrentHashMap采用二次hash的方式来进行分段并发控制,相比table的话,效率更高一点,适合写比较多的环境。
COW(Copy On Write)
上面讲的集合使用,其实还有一种方式可以考虑,就是COW写时复制的方式,这种方式适合读多写少的环境,可以提高并发性能,guava里面有Lists.newCopyOnWriteArrayList()可以直接使用,map的话需要自己做控制,具体实现可以百度。
CAS(Compare And Swap)
CAS是一种系统原语,原语属于操作系统用语范畴,是由若干条指令组成的,用于完成某个功能的一个过程,并且原语的执行必须是连续的,在执行过程中不允许被中断,也就是说CAS是一条CPU的原子指令,不会造成所谓的数据不一致问题。CAS在Java中的应用,即并发包中的原子操作类(Atomic系列),从JDK 1.5开始提供了java.util.concurrent.atomic包,在该包中提供了许多基于CAS实现的原子操作类,使用起来很简单,具体可以自行百度。
volatile内存屏障的使用
可能很多新手没有见过这个关键字,老程序猿对这个关键字也不熟悉,我也是之前看过很多资料,里面讲到过volatile关键字的内存屏障功能,但是这个关键字我感觉是java里面最难使用的一个关键字了,Disruptor里面采用volatile来替换锁的案例非常成功,有兴趣的可以看一下这篇文章《disruptor-memory-barrier》。
锁的使用
直到最后,才是锁的使用。这个也是大部分程序猿最熟悉的进程内并发控制的方式。目前锁主要有synchronized关键字和concurrent包里面的lock,至于如何选择synchronized和lock的使用场景,synchronized关键字是由JVM来控制内部执行的,每个object都有一个monitor,synchronized关键字就是去获得这个monitor对象,有点类似于操作系统的PV操作,这个锁是非公平锁,适合竞争不激烈的情况,竞争激烈的时候性能没有lock高。Lock是Concurrent包里面提供的,由JDK提供的锁,有多种实现,这个使用非常灵活,适合复杂的业务场景,但是这个lock一定要在try-finally中关闭,防止锁死。所以一些简单的业务场景,可以使用synchronized关键字,复杂的业务场景可以考虑使用lock,具体的使用方式网上资料一大把,这里不细说了。
总结
之前一直对高并发应用和性能情有独钟,也做过高并发产品,总之这条路太深了,涉及到的知识点很多,坑也很多,且行且珍惜。